Dereverberácia reči s využitím lineárnej predikcie
27. Február, 2017, Autor článku: Andráš Imrich, Informačné technológie
Ročník 10, číslo 2  Pridať príspevok
Pridať príspevok
![]() Predmetom tejto práce je algoritmus na skvalitnenie reči znehodnotenej dozvukom s využitím lineárnej predikcie. V úvode práce sú popísané základné mechanizmy vzniku dozvuku a ich vplyv na rečový signál. Nasleduje popis algoritmu s úpravou a spriemerňovaním hlasivkových cyklov, ktorý je určený na potlačenie dozvuku v rečovom signáli snímanom mikrofónovým poľom. Výhodou algoritmu je výpočtová nenáročnosť a úspešnosť pri vysokých úrovniach šumu a dozvuku. Záver práce je venovaný popisu jednotlivých evaluačných metód a prezentácii úspešnosti algoritmu pri rôznych podmienkach.
Predmetom tejto práce je algoritmus na skvalitnenie reči znehodnotenej dozvukom s využitím lineárnej predikcie. V úvode práce sú popísané základné mechanizmy vzniku dozvuku a ich vplyv na rečový signál. Nasleduje popis algoritmu s úpravou a spriemerňovaním hlasivkových cyklov, ktorý je určený na potlačenie dozvuku v rečovom signáli snímanom mikrofónovým poľom. Výhodou algoritmu je výpočtová nenáročnosť a úspešnosť pri vysokých úrovniach šumu a dozvuku. Záver práce je venovaný popisu jednotlivých evaluačných metód a prezentácii úspešnosti algoritmu pri rôznych podmienkach.
1. Účel dereverberácie
Spracovanie rečových signálov je predmetom výskumu už niekoľko dekád, o čom svedčí nepreberné množstvo publikácií v tejto oblasti. Pri skvalitňovaní audiosignálov sa vo väčšine prípadov jednalo o redukciu šumu a subpriestorové algoritmy sa donedávna využívali iba na vytváranie priestorových efektov (napr. stereo). Potlačenie nežiaducich priestorových efektov zo snímaných signálov – odstránenie dozvuku sa stalo predmetom vedeckých výskumov a článkov až v priebehu posledných rokov. Vo významnej miere to bolo vyvolané znížením ceny a masovým rozšírením prenosných zariadení ako sú mobily, laptopy, PDA, používateľské rozhrania v automobilovom priemysle atď. so súčasným zvýšením ich výpočtového výkonu. Vznikol tak priestor na služby ako hlasové ovládanie, konverzia reči na text, identifikácia hovoriaceho a pod., z čoho vyplynuli požiadavky na vývoj dereverberačných algoritmov.
Účinné dereverberačné metódy sú vo všeobecnosti výpočtovo náročné, a ich potenciálne využitie je prevažne v mobilných aplikáciách, takže si ťažko predstaviť komerčné využitie dereverberácie pred dvadsiatimi rokmi. Neustále zvyšovanie ako štandardov na trhu osobných elektronických zariadení, tak ich výkonu, však otvára cestu aj tejto oblasti skvalitňovania audiosignálov. Algoritmus s úpravou a spriemerňovaním hlasivkových cyklov (ÚSHC), ktorý je predmetom tejto práce, má byť kompromisom medzi čo najlepším výsledkom a čo najnižšími požiadavkami na výpočtový systém.
2. Vznik dozvuku
Ak je rečový signál snímaný v uzavretom priestore jedným alebo viacerými mikrofónmi umiestnenými v určitej vzdialenosti od rečníka, pozorovaný signál sa skladá z mnohých superponovaných kópií rečového signálu. Tieto sú oneskorené a utlmené kvôli odrazom od stien a ďalších objektov v priestore, ako je znázornené na Obr. 1. Je zrejmé, že odrazy dorazia k mikrofónu s oneskorením, pretože cesta každého odrazu je dlhšia ako priama, a tiež utlmené, kvôli frekvenčne závislej absorpcii odrazových povrchov [1].
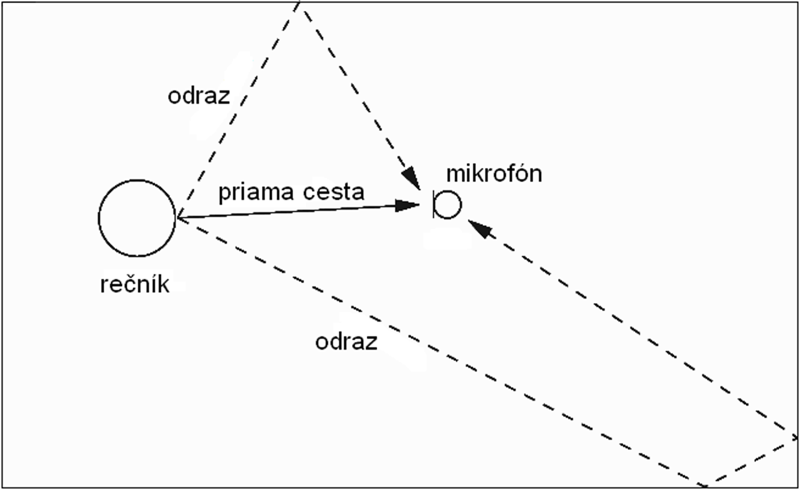
Obr. 1 Vznik dozvuku v uzavretom priestore
Rečový signál s dozvukom sa javí ako ten istý signál prichádzajúci z viacerých zdrojov rôzne rozmiestnených v priestore a tým v rozdielnych časoch a s rozdielnymi intenzitami. To dodáva priestorovosť do nasnímanej reči a percepčne sa javí, akoby rečník hovoril cez prekážku alebo akoby bol veľmi vzdialený od mikrofónu. Mierny dozvuk v reči ešte nezhoršuje zrozumiteľnosť a je vnímaný ako prirodzený a pri posluchu príjemný [2]. Návrhom akustického prostredia je ho možné kontrolovať, čo sa praktizuje pri ozvučovaní a prizvučovaní, dozvuk však zhoršuje spracovateľnosť reči systémami automatického rozpoznávania reči.
Problémy spojené s dozvukom často možno obísť umiestnením mikrofónu blízko k ústam rečníka, napr. použitím náhlavnej súpravy. Tým sa výrazne zvýši intenzita signálu z priamej cesty oproti odrazom a šumu, čo ich učiní prakticky zanedbateľnými. Takéto riešenie však nemusí byť vždy praktické, čo otvára cestu dereverberačným algoritmom.
Nech čistý rečový signál s(n) od rečníka prechádza akustickými kanálmi Hm(z),m = 1,…,M . Výstupy týchto kanálov sú merané M mikrofónmi ako signály xm(n). Aditívny šum je reprezentovaný vm(n) a nech je to jediný druh šumu v modeli reverberácie a dereverberácie. Signál xm(n) meraný mikrofónom m je superpozíciou signálu priamej cesty, s príslušným oneskorením a útlmom, a teoreticky nekonečného počtu odrazov prichádzajúcich s vlastnými oneskoreniami a útlmami. Tento model je znázornený na Obr. 2.
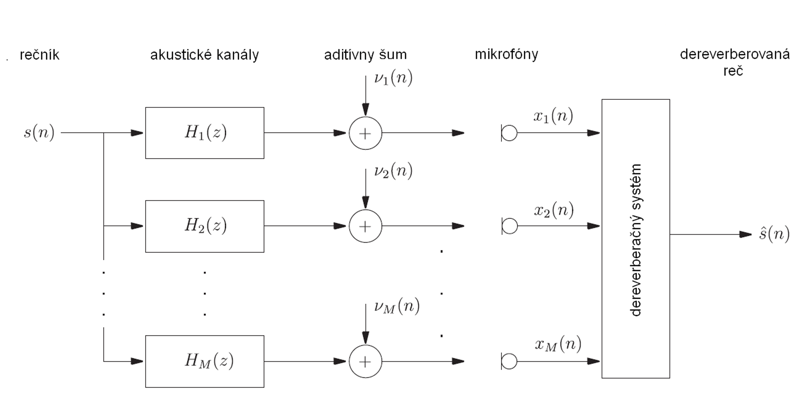
Obr. 2 Model reverberácie a dereverberácie
Ak útlm a oneskorenie pre každý kanál m=1,…,M a odrazovú cestu i=0,1,…,∞ opíšeme akustickou impulzovou odozvou hm,i, signál xm(n) sa dá vyjadriť ako
 = \sum_{i=0}^{\infty} h_{m,i} (n) s(n-1)") |
(1) |
Cieľom dereverberácie je nájsť systém, ktorý zo vstupov xm(n), m=1,…,M vráti výstup ")
3. Lineárna predikcia reči
Základný princíp lineárnej predikčnej (LP) analýzy je založený na predpoklade, že n-tá vzorka rečového signálu s(n) môže byť vyjadrená lineárnou kombináciou predchádzajúcich P vzoriek a budiacej postupnosti u(n), čo môže byť vyjadrené vzťahom
 = -\sum_{i=1}^{P} a_i . s(n-1) + G . u(n)") |
(2) |
kde G je zosilnenie, P je rád modelu a ai sú lineárne predikčné koeficienty, o ktorých predpokladáme, že sú krátkodobo konštantné. Vyjadrením rovnice (2) v Z-oblasti a úpravou dostaneme prenosovú funkciu sústavy v tvare
 = \frac{G}{1+\sum_{i=1}^{P} a_i . z^{-1}} = \frac{G}{A(z)}") |
(3) |
kde
 = 1+ \sum_{i=1}^{P} a_i . z^{-1}") |
(4) |
je tzv. inverzný filter. Na výpočet LP koeficientov ai a koeficientu zosilnenia G sa používa metóda najmenších štvorcov. Pri analýze rečového signálu nie je známa budiaca funkcia u(n), vychádzame preto z odhadu rečového signálu, ktorý je lineárnou kombináciou iba predchádzajúcich P vzoriek:
 = - \sum_{i=1}^{P} a_i . s(n-1)") |
(5) |
Definujeme predikčnú chybu e(n) ako rozdiel medzi skutočným signálom a jeho odhadom
 = s(n) - \hat{s}(n) = s(n) + \sum_{i=1}^{P} a_i . s(n-1)") |
[3] (6) |
Spätná syntéza reči z LP koeficientov a predikčnej chyby je proces imitujúci činnosť vokálneho traktu, pričom model hlasového traktu je krátkodobo popísaný predikčnými koeficientmi ai. Hlasový trakt reprezentovaný prenosovou funkciou H(z) je budený predikčnou chybou e(n) a výstupom je rekonštruovaný signál. Dôležitou vlastnosťou LP analýzy je, že LP koeficienty ai sa pri znehodnotení reči dozvukom menia iba v malej miere. Podstatou dereverberačných algoritmov s lineárnou predikciou je spracovanie predikčnej chyby, ktorá je dozvukom ovplyvňovaná podstatne. Príklady priebehov predikčných chýb čistého a reverberovaného rečového signálu sú na Obr. 3.
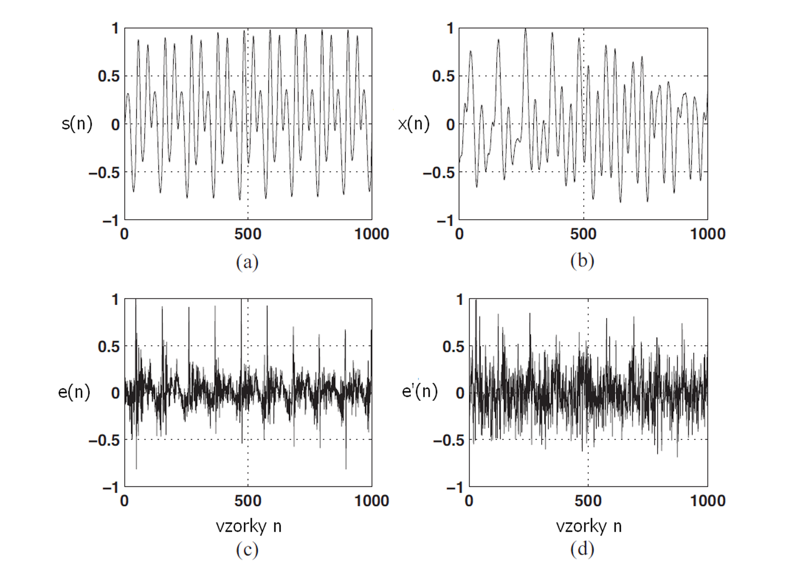
Obr. 3 Priebeh znelého segmentu (a) čistého rečového signálu, (b) rečového signálu s dozvukom, (c) predikčnej chyby čistého rečového signálu, (d) predikčnej chyby rečového signálu s dozvukom
Charakteristickým znakom predikčnej chyby čistého rečového signálu v znelých segmentoch sú kváziperiodické excitačné špičky, ktoré majú tvar úzkych impulzov. Ich polohy v čase zodpovedajú hlasivkovým impulzom. Ak je rečový signál znehodnotený dozvukom, excitačné špičky sú buď do určitej miery rozprestreté v čase, alebo nasleduje viacero excitačných špičiek (a tým zdanlivo hlasivkových impulzov) za sebou. Poloha týchto dozvukových excitačných špičiek je zdanlivo náhodná, avšak majú tendenciu korelovať so skutočným hlasivkovým impulzom. Utlmením chybových dozvukových špičiek pri zachovaní resp. dotvarovaní skutočnej excitačnej špičky sa dá realizovať dereverberácia rekonštruovaného rečového signálu v znelých segmentoch.

Obr. 4 Bloková schéma dereverberačného algoritmu založeného na LP
Na Obr. 4 je všeobecná bloková schéma dereverberačného algoritmu so spracovaním predikčnej chyby M pozorovaných signálov. Lineárne predikčné koeficienty 
")
4. Algoritmus úpravy a spriemerňovania hlasivkových cyklov
Predikčná chyba určuje charakter rekonštruovaného signálu jednak polohou a tvarom skutočnej excitačnej špičky, ale aj informáciou medzi dvoma hlasivkovými impulzami. Problémom u algoritmov s úpravou predikčnej chyby je, že modifikácia skutočných excitačných špičiek alebo priebehu predikčnej chyby medzi nimi spôsobuje skreslenie rekonštruovaného signálu, ktorý potom znie neprirodzene. Väčšina metód navyše do dereverberačného procesu nezahŕňa neznelé a tiché segmenty reči, ktoré sa ponechávajú dozvukom znehodnotené. Popisovaný algoritmus, ktorého bloková schéma je na Obr. 5, má ošetriť práve tieto problémy.
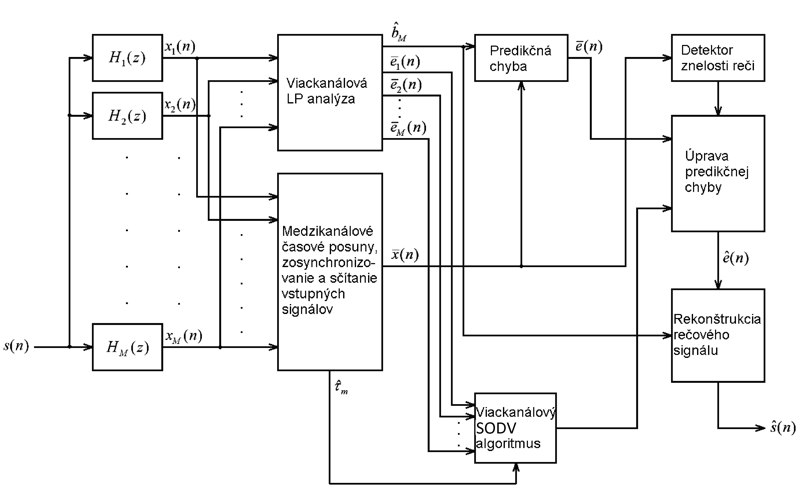
Obr. 5 Bloková schéma algoritmu s ÚSHC
4.1 Viackanálová LP analýza
Rečový signál s dozvukom je snímaný mikrofónovým poľom s M mikrofónmi ako xm(n)n m=1,…,M. Predmetom 1. kroku je určenie LP koeficientov 
 |
(7) |
kde bm,i je i-tý predikčný koeficient v m-tom kanáli určený zo vstupného signálu xm(n) a P je rád LP analýzy. Tieto predikčné koeficienty budú neskôr využité k určeniu predikčnej chyby a k rekonštrukcii dereverberovanej reči.
4.2 Medzikanálové časové posuny a formovanie smerovej charakteristiky
Ku korektnému sčítaniu M kanálov do jedného potrebujeme poznať časové oneskorenia jednotlivých kanálov oproti referenčnému. Tieto posuny budú dôležité aj pre ďalšie časti algoritmu. V [1] bola na ich výpočet navrhnutá metóda krížových korelácií popísaná v [4] ako pomerne jednoduchá a dostatočne presná pre mierny dozvuk. Nech xref(n) je signál referenčného a xm(n) je signál porovnávaného kanálu. Odhad posunu signálu m-tého kanálu oproti referenčnému 
") |
(8) |
pričom ")
 = \frac{1}{2 \pi} \int_{-\pi}^{\pi} \frac{X_{ref}(e^{j \omega}) X_{m}^*(e^{j\omega})}{|X_{ref}(e^{j \omega})| |X_{m}^*(e^{j\omega})|} e^{j \omega \tau} d\omega") |
(9) |
kde X* je číslo komplexne združené k X. Vypočíta sa M-1 posunov medzi referenčným signálom x1(n) a porovnávanými signálmi x2(n) až xM(n), tak ako v predchádzajúcom kroku po 20ms segmentoch. Vzájomným posunom a sčítaním signálov x1(n) až xM(n) do výsledného signálu ")
 = \frac{1}{M} \sum_{m-1}^{M} x_m (n-\hat{\tau}_m)") |
(10) |
nielenže dostaneme jeden signál s potlačeným nekorelovaným šumom, ale zároveň formujeme smerovú charakteristiku mikrofónového poľa. Táto je pritom vďaka počítaniu (8) po segmentoch dynamická, t. z. hlavný lalok smerovej charakteristiky sleduje rečníka, ktorý pritom môže byť v pohybe vzhľadom k mikrofónovému poľu. Formovanie smerovej charakteristiky samotné znižuje úroveň dozvuku, keďže odrazy prichádzajúce zo smerov mimo hlavný lalok smerovej charakteristiky sú utlmené.
4.3 Výpočet predikčnej chyby
Jednotnú predikčnú chybu ")
 = \hat{b}_M^T \bar{x}(n)") |
(11) |
Táto predikčná chyba bude neskôr upravovaná tak, aby pri LP syntéze došlo k rekonštrukcii skvalitneného rečového signálu.
4.4 Identifikácia skutočných hlasivkových impulzov
V predchádzajúcich krokoch sme sa dostali od signálov z M mikrofónov k jedinej množine LP koeficientov
Výsledkom je jedna množina kandidátov odpovedajúca signálu
4.5 Detekcia znelých a neznelých segmentov rečového signálu
Presná detekcia znelých a neznelých častí reči je pre dereverberačné algoritmy založené na LP kritická. Samotný algoritmus SODV nie je dostačujúci, pretože hoci má dobré výsledky pri znelej reči, v neznelých a tichých segmentoch deteguje neexistujúce hlasivkové impulzy. Zvolili sme preto detektor popísaný v [6], u ktorého bola prezentovaná prijateľná presnosť pri minimálnej výpočtovej a implementačnej náročnosti. Tento detektor je nutné najprv natrénovať manuálnym segmentovaním trénovacích nahrávok reči, po prvotnom natrénovaní sa dokáže sám adaptovať na zmenu rečníka či prostredia.
Vstupný signál detektora,
4.6 Spriemerňovanie hlasivkových cyklov
Tento krok je jadrom celého ÚSHC algoritmu a predstavuje vlastnú dereverberáciu. Súčtový signál , \; l=1,2, \dots")

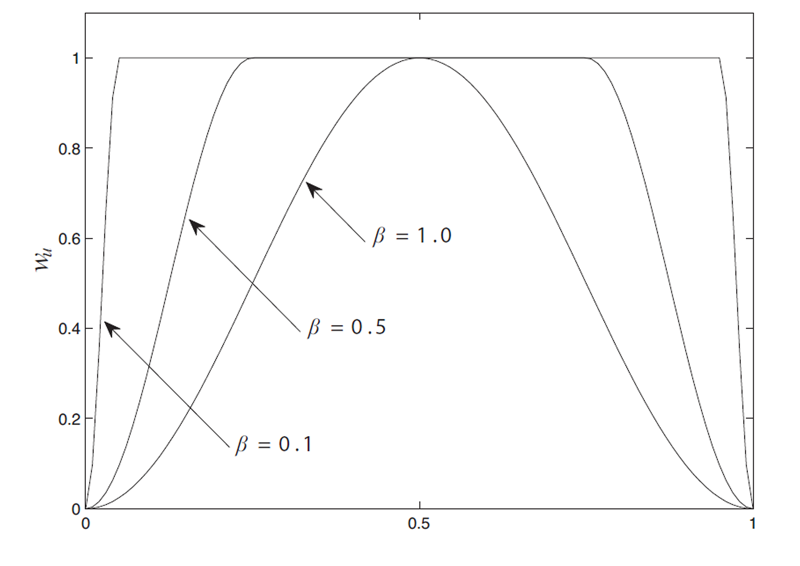
Obr. 6 Vážiaca funkcia pre rôzne činitele tvaru
Konečné vyjadrenie l-tého skvalitneného hlasivkového cyklu v znelých segmentoch reči je
 = (I-W) \bar{e}(n_l) + \frac{1}{2 \chi +1} \sum_{i=-\chi}^{\chi} W \bar{e}(n_{l+i})") |
(12) |
kde W je diagonálna matica s vážiacou funkciou wu
 |
(13) |
a I je jednotková matica. Skvalitnený hlasivkový cyklus teda vznikne spriemernením hlasivkového cyklu ")

")
 = \gamma \hat{g}(n_{l-1}) + (1-\gamma) \hat{g}") |
(14) |
pričom 
![\hat{g}(0) = [1,0,0, \dots ]^T](http://s0.wp.com/latex.php?latex=%5Chat%7Bg%7D%280%29+%3D+%5B1%2C0%2C0%2C+%5Cdots+%5D%5ET+&bg=ffffff&fg=000000&s=0 "\hat{g}(0) = [1,0,0, \dots ]^T")

 |
(15) |


")
 = \hat{g}^T(n_l) \bar{e}(n_l)") |
(16) |
Rovnice (12) až (16) sú exaktné pre periodické hlasivkové impulzy, a tým pre hlasivkové cykly s rovnakou dĺžkou. Reálne sú hlasivkové impulzy iba kváziperiodické a cykly sa líšia dĺžkou o niekoľko vzoriek. Toto bolo pri implementácii ošetrené symetrickým doplnením nulami, resp. orezaním spriemerňovaných hlasivkových cyklov.
4.7 Rekonštrukcia skvalitneného rečového signálu
Odhad čistého rečového signálu získame aplikáciou inverzného filtra s LP koeficientmi 
![\hat{s}(n) = [b_{M}^{-1}]^T \hat{e}(n)](http://s0.wp.com/latex.php?latex=%5Chat%7Bs%7D%28n%29+%3D+%5Bb_%7BM%7D%5E%7B-1%7D%5D%5ET+%5Chat%7Be%7D%28n%29+&bg=ffffff&fg=000000&s=0 "\hat{s}(n) = [b_{M}^{-1}]^T \hat{e}(n)") |
(17) |
5. Evaluácia výsledkov
Popísaný algoritmus a pomocný trénovací program boli implementované v Matlabe. Na vyhodnotenie úspešnosti algoritmov sme použili voľne dostupnú audio databázu nahranú Tomom Sullivanom na univerzite Carnegie Mellon. Všetky nahrávky boli navzorkované s frekvenciou 16kHz a s 16-bitovým lineárnym kvantovaním. Každá nahrávka obsahuje signály 15-prvkového mikrofónneho poľa a referenčný čistý rečový signál, snímaný mikrofónom v blízkosti úst rečníka (náhlavná súprava). Signál snímaný náhlavným mikrofónom bol pri vyhodnocovaní výsledkov použitý ako referenčný a považovaný za čistý.
Mikrofónne pole obsahuje tri 7-prvkové subpolia s ekvidištančne rozmiestnenými mikrofónmi, líšiace sa ich vzájomnou vzdialenosťou. Každá nahrávka je potom ešte charakterizovaná prostredím a vzdialenosťou medzi rečníkom a prostredným mikrofónom, pričom rečník sa nachádza na osi mikrofónneho poľa. Vo všetkých nahrávkach hovoria mužskí rečníci a ich dĺžka je asi 3s. Vybrané nahrávky boli spracované popísaným algoritmom a jeho úspešnosť bola vyhodnotená percepčnými objektívnymi metódami.
5.1 Miera PESQ
Je to objektívna miera používaná v telefónii. Čistý a znehodnotený signál sú najprv normalizované na rovnakú hlasitosť a filtrované; odozva filtra je podobná štandardnému telefónnemu slúchadlu. Signály sa potom časovo zosynchronizujú a transformujú na spektrum hlasitosti. Rozdiely v hlasitosti sa spriemernia cez čas a frekvenciu tak, aby výsledok predikoval subjektívne hodnotenie. Výsledok je z intervalu 1,0 až 4,5, kde vyššia hodnota znamená lepšie hodnotenie [7]. Prehľad hodnotení pre rôzne nahrávky podľa miery PESQ je v Tab. 1.
Tab. 1 Hodnotenia podľa miery PESQ
| Prostredie | Vzdialenosť medzi mikrofónmi (cm) | Skóre PESQ | |
|---|---|---|---|
| Pred spracovaním | Po spracovaní | ||
| Konferenčná miestnosť, rečník 1m od mikrofónneho poľa | 4 | 2,17 | 2,18 |
| 8 | 2,11 | 2,26 | |
| Konferenčná miestnosť, rečník 3m od mikrofónneho poľa | 4 | 1,77 | 1,94 |
| 8 | 1,7 | 1,99 | |
| Hlučná počítačová pracovňa, rečník 1m od mikrofónneho poľa | 4 | 2,2 | 2,25 |
| 8 | 2,2 | 2,25 | |
Vo všetkých prípadoch došlo k miernemu zlepšeniu, najvýraznejšie v konferenčnej miestnosti pri vzdialenosti rečníka od stredu mikrofónneho poľa 3m – prípad s najväčším znehodnotením dozvukom. Výsledky indikujú, že algoritmus je úspešnejší pri väčšom rozstupe mikrofónov.
5.2 Pomer SNRseg
V čase segmentovaný pomer signál/šum, je vypočítaný ako
}{\sum_{n=Nm}^{Nm+N-1} (x(n)-\hat{x}(n))^2}") |
(18) |
kde x(n) je čistý signál,
Tab. 2 Hodnotenia podľa pomeru SNRseg.
| Prostredie | Vzdialenosť medzi mikrofónmi (cm) | Pomer SNRseg (dB) | |
|---|---|---|---|
| Pred spracovaním | Po spracovaní | ||
| Konferenčná miestnosť, rečník 1m od mikrofónneho poľa | 4 | -7,89 | -7,78 |
| 8 | -8,3 | -8,06 | |
| Konferenčná miestnosť, rečník 3m od mikrofónneho poľa | 4 | -6,5 | -5,3 |
| 8 | -6,08 | -5,52 | |
| Hlučná počítačová pracovňa, rečník 1m od mikrofónneho poľa | 4 | -8,72 | -5,85 |
| 8 | -8,53 | -5,75 | |
Vo všetkých prostrediach došlo k zlepšeniu odstupu signálu od šumu, avšak nevieme posúdiť, či došlo naozaj k redukcii šumu alebo dozvuku. Zlepšenie SNRseg v konferenčnej miestnosti je 0,1 až 1,2 dB, v hlučnej počítačovej pracovni až 2,9dB. Algoritmus nie je primárne určený na redukciu šumu, výsledky ale naznačujú, že pri vysokých úrovniach šumu je tento potláčaný.
5.3 Vzdialenosť WSS
Predstavuje rozdiel v zmenách spektrálnej obálky percepčne vážený po frekvenčných pásmach. Vzdialenosť WSS je definovaná ako
 (S_c (j,m) - S_P (j,m))^2 }{\sum_{j=1}^{K} W_{WSS}}") |
(19) |
s K=25, počtom segmentov M a váhami WWSS(j,m). SC(j,m) a SP(j,m) sú spektrálne zmeny v j-tom frekvenčnom pásme pre čistý a posudzovaný signál [7]. Touto mierou by principiálne bolo možné veľmi účinne zhodnotiť úroveň dozvuku, ak by v signáli s dozvukom nebol aditívny šum. Reálne je posudzovaný príspevok ako dozvuku, tak aj šumu. Prehľad výsledkov je v Tab. 3.
Tab. 3 Hodnotenia podľa vzdialenosti WSS
| Prostredie | Vzdialenosť medzi mikrofónmi (cm) | Vzdialenosť WSS | |
|---|---|---|---|
| Pred spracovaním | Po spracovaní | ||
| Konferenčná miestnosť, rečník 1m od mikrofónneho poľa | 4 | 61,5 | 46,92 |
| 8 | 55,27 | 45,92 | |
| Konferenčná miestnosť, rečník 3m od mikrofónneho poľa | 4 | 69,54 | 58 |
| 8 | 63,47 | 57,89 | |
| Hlučná počítačová pracovňa, rečník 1m od mikrofónneho poľa | 4 | 75,47 | 51,15 |
| 8 | 76 | 53,03 | |
Podľa tejto miery sú lepšie výsledky dosiahnuté s menším rozostupom mikrofónov a pri menšej vzdialenosti rečníka od mikrofónneho poľa. Najvyššia účinnosť algoritmu vychádza v hlučnej počítačovej pracovni, vzdialenosť WSS je teda pravdepodobne pre evaluáciu dereverberačných algoritmov priveľmi citlivá na šum.
6. Záver
Popísaný algoritmus preukázateľne potláča dozvuk v rečových signáloch znehodnotených dozvukom a šumom. Je odolný voči vysokým hladinám šumu, ktoré dokonca do určitej miery potláča. Výpočtovo je pomerne nenáročný, a to aj napriek využitiu dynamického programovania (potrebný počet výpočtových operácií je závislý od charakteru signálu). Daňou za to je, že ani teoreticky neumožňuje dokonalú dereverberáciu a je vhodný skôr pre prostredia s výraznejším dozvukom. Veľkou výhodou ÚSHC algoritmu je, že pri jeho vhodnom nastavení nedochádza k vnímateľnému skresleniu rečového signálu ani pri výraznom dozvuku, a môže byť vhodnou metódou predspracovania signálu pre iné skvalitňujúce algoritmy.
Poďakovanie
Táto publikácia vznikla vďaka podpore v rámci operačného programu Výskum a vývoj pre projekt „(Centrum informačných a komunikačných technológií pre znalostné systémy) (kód ITMS:26220120020), spolufinancovaný zo zdrojov Európskeho fondu regionálneho rozvoja“.
Literatúra
- NAYLOR, Patrick A. – GAUBITCH, Nikolay D.: Speech dereverberation. London: Springer, 2010. 388 s. ISBN 978-1-84996-056-4.
- SMETANA, Ctirad: Ozvučování. Praha: SNTL, 1987. 216 s.
- JUHÁR, Jozef: Rečové technológie. Košice: Equilibria, s.r.o., 2011. 517 s. ISBN 978-80-89284-75-7.
- KNAPP, Charles H. – CARTER, Clifford G.: The generalized correlation method for estimation of time delay. In: IEEE Transactions on acoustics, speech, and signal processing. roč. 24, č. 4 (1976), s. 320-327.
- NAYLOR, Patrick A. – KOUNOUDES, Anastasis – GUDNASON, Jon – BROOKES, Mike: Estimation of glottal closure instants in voiced speech using the DYPSA algorithm. In: IEEE Transactions on audio, speech, and language processing. roč. 15, č. 1 (2007), s. 34-43.
- ATAL, Bishnu S. – RABINER, Lawrence R.: A pattern recognition approach to voiced-unvoiced-silence classification with applications to speech recognition. In: IEEE Transactions on acoustics, speech, and signal processing. roč. 24, č. 3 (1976), s. 201-212.
- HU, Y. – Loizou, P.: Evaluation of objective quality measures for speech enhancement. In: IEEE Transactions on speech and audio processing. roč. 16, č. 1 (2008), s. 229-238.
Katedra elektroniky a multimediálnych telekomunikácií, Fakulta elektrotechniky a informatiky, Technická univerzita v Košiciach

